Informatika

Köszi a javaslatokat, kipróbálom õket.
Az sql -t 1,5-2 éve tanulom, nyilván egy fél éves kurzus során egyszerû lekérdezésekre futott csak. A tudásomat folyamatosan bõvítem, a Right és a Left Join parancsokat mind a mai napig nem értem, éppen ezért nem használom õket, bár hasonlóképp vagyok a not exist parancsokkal is. A lekérdezések unióját sem régen ismerem (union). A limitet csak akkor használom, ha csak egy rekordot szeretnék listázni, ez pedig az IF parancs miatt szükséges, mert ha pl. 2 rekordot kapna az elsõ argumentumban akkor baj lenne.
Sajnos az érdemjegyeket helymegtakarítás miatt a felhasználó azonosítójával párosítom, (emiatt a like elkerülhetetlen) pl. így szerepel az adatbázisban: .202|4.12|5.63|2. stb...
A táblákat mindig indexelem, az elsõ oszlop mindig az elsõdleges kulcsom, ahol egy automatikusan növekvõ számsorozat jön létre (auto increment hatására), pl. ha 2x vinném be ugyanazt a számot duplicate entry hibaüzenetet kapnék a mysql_error() - tól.
Az egymásba ágyazott lekérdezések (bár a tábla összekapcsolások is) sokszor kényelmetlenek, de nagyon hasznosak, mivel nem kell millió egy lekérdezést egymás után elküldeni, továbbá nem kell a kapott PHP-s asszociatív tömböt meg a következõ lekérdezésbe betenni. A Select utáni "*" valóban lassítja a futásidõt, hiszen ha nem kell minden mezõ adata nekem, akkor nem is kérem, én ilyenkor sosem szoktam kitenni a csillagot, csak azt, amivel dolgozni szeretnék. A futásidõvel nem szokott baj lenni, néhány ezred másodperc alatt lefut. A having parancsokat és a min, max fv-eket gyakran használom a GROUP BY-al együtt, legfõképpen statisztikák készítésénél.
A sprintf és társai a C nyelvbõl ismerõsek, noha ebben a nyelvben nagyon amatõr vagyok még.
Az sql -t 1,5-2 éve tanulom, nyilván egy fél éves kurzus során egyszerû lekérdezésekre futott csak. A tudásomat folyamatosan bõvítem, a Right és a Left Join parancsokat mind a mai napig nem értem, éppen ezért nem használom õket, bár hasonlóképp vagyok a not exist parancsokkal is. A lekérdezések unióját sem régen ismerem (union). A limitet csak akkor használom, ha csak egy rekordot szeretnék listázni, ez pedig az IF parancs miatt szükséges, mert ha pl. 2 rekordot kapna az elsõ argumentumban akkor baj lenne.
Sajnos az érdemjegyeket helymegtakarítás miatt a felhasználó azonosítójával párosítom, (emiatt a like elkerülhetetlen) pl. így szerepel az adatbázisban: .202|4.12|5.63|2. stb...
A táblákat mindig indexelem, az elsõ oszlop mindig az elsõdleges kulcsom, ahol egy automatikusan növekvõ számsorozat jön létre (auto increment hatására), pl. ha 2x vinném be ugyanazt a számot duplicate entry hibaüzenetet kapnék a mysql_error() - tól.
Az egymásba ágyazott lekérdezések (bár a tábla összekapcsolások is) sokszor kényelmetlenek, de nagyon hasznosak, mivel nem kell millió egy lekérdezést egymás után elküldeni, továbbá nem kell a kapott PHP-s asszociatív tömböt meg a következõ lekérdezésbe betenni. A Select utáni "*" valóban lassítja a futásidõt, hiszen ha nem kell minden mezõ adata nekem, akkor nem is kérem, én ilyenkor sosem szoktam kitenni a csillagot, csak azt, amivel dolgozni szeretnék. A futásidõvel nem szokott baj lenni, néhány ezred másodperc alatt lefut. A having parancsokat és a min, max fv-eket gyakran használom a GROUP BY-al együtt, legfõképpen statisztikák készítésénél.
A sprintf és társai a C nyelvbõl ismerõsek, noha ebben a nyelvben nagyon amatõr vagyok még.
Havazás előrejelzés

Utolsó észlelés
Térképek
Radar
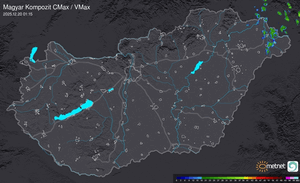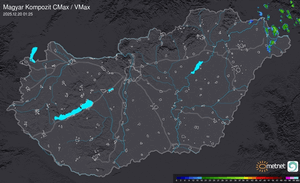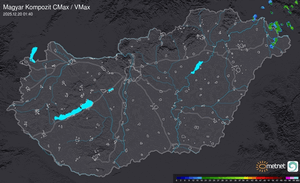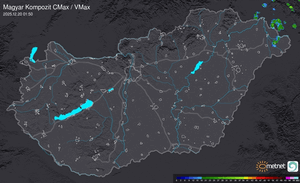
Aktuális hõmérséklet
Aktuális szél
Utolsó kép

Mediterrán ciklon hoz csöppnyi tavaszt és kicsivel több telet
Időjárás-változás | 2026-02-18 12:39
Szabályzat