Informatika

select A.*, B.* from A left join B on oszlop: az A tábla minden sora benne lesz az eredményben, a B táblából csak azok, amelyeket megtalál, mindenhol másutt a B.* oszlopokban NULL jön vissza. Right join ugyanez, csak a B tábla minden sora lesz benne az eredményben.
A not exist csak egy logikai feltétel és akkor lesz igaz, ha a mögötte lévõ select nem ad vissza egyetlen rekordot sem.
A union egy result setbe gyûjti az elõtte és az utána lévõ lekérdezés eredményeit, feltétel, hogy azonos oszlopok legyenek mindkét helyen, pl : select a.a union b.a . Ez distinct eredményt ad vissza, a mindkét selectben meglévõ sorokat csak egyszer fogja hozni. Ha azt írod, hogy union all, akkor az minden sort visszaad, a mindkét selectben meglévõ sort kétszer fogja visszaadni.
"Sajnos az érdemjegyeket helymegtakarítás miatt a felhasználó azonosítójával párosítom, (emiatt a like elkerülhetetlen) pl. így szerepel az adatbázisban: .202|4.12|5.63|2. stb... " : nem érdemes a hellyel ennyire spórolni, ez 2-8 byte soronként (tinyint(2)) , ez nagyjából semmi és sokkal több feljesztés kell hozzá, nem éri meg ilyen szinten. Arról nem is beszélve hogy ha ezt az oszlopot is indexeled, az úgyis elviszi a spórolt helyet.
Ehelyett egy másik kis táblába lehet gyûjteni a jegyeket, oszlopai lehetnek pl userid, tantargyid, jegy, ez 2 int és egy smallint oszlop, összesen 9 byte/sor, ennél jobban nem érdemes spórolni.
A select * azért nem jó, mert akkor mindig megnézi a tábla sémáját, hogy tudja, milyen oszlopok vannak a táblában, ez idõveszteség + feleslegesen rágja a diszket.
Az egymásba ágyazott lekérdezéssel az lehet a baj, hogy lehet olyat írni, amikor a belsõ select az eredmény minden sorára lefut egyszer, ami nem kifejezetten performanciális (szép magyar szó)
Az auto increment nem biztonságos, a post átírásával könnyû más rekordokat hackelni, a GUID (php-ban uuid()) jobb ilyesmire.
A sprintf nem csinál mást, csak összepakol egy stringet helyetted, nem kell az idézõjelek százait leirnod.
A not exist csak egy logikai feltétel és akkor lesz igaz, ha a mögötte lévõ select nem ad vissza egyetlen rekordot sem.
A union egy result setbe gyûjti az elõtte és az utána lévõ lekérdezés eredményeit, feltétel, hogy azonos oszlopok legyenek mindkét helyen, pl : select a.a union b.a . Ez distinct eredményt ad vissza, a mindkét selectben meglévõ sorokat csak egyszer fogja hozni. Ha azt írod, hogy union all, akkor az minden sort visszaad, a mindkét selectben meglévõ sort kétszer fogja visszaadni.
"Sajnos az érdemjegyeket helymegtakarítás miatt a felhasználó azonosítójával párosítom, (emiatt a like elkerülhetetlen) pl. így szerepel az adatbázisban: .202|4.12|5.63|2. stb... " : nem érdemes a hellyel ennyire spórolni, ez 2-8 byte soronként (tinyint(2)) , ez nagyjából semmi és sokkal több feljesztés kell hozzá, nem éri meg ilyen szinten. Arról nem is beszélve hogy ha ezt az oszlopot is indexeled, az úgyis elviszi a spórolt helyet.
Ehelyett egy másik kis táblába lehet gyûjteni a jegyeket, oszlopai lehetnek pl userid, tantargyid, jegy, ez 2 int és egy smallint oszlop, összesen 9 byte/sor, ennél jobban nem érdemes spórolni.
A select * azért nem jó, mert akkor mindig megnézi a tábla sémáját, hogy tudja, milyen oszlopok vannak a táblában, ez idõveszteség + feleslegesen rágja a diszket.
Az egymásba ágyazott lekérdezéssel az lehet a baj, hogy lehet olyat írni, amikor a belsõ select az eredmény minden sorára lefut egyszer, ami nem kifejezetten performanciális (szép magyar szó)
Az auto increment nem biztonságos, a post átírásával könnyû más rekordokat hackelni, a GUID (php-ban uuid()) jobb ilyesmire.
A sprintf nem csinál mást, csak összepakol egy stringet helyetted, nem kell az idézõjelek százait leirnod.
Havazás előrejelzés

Utolsó észlelés
Térképek
Radar
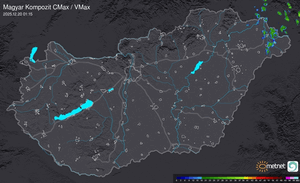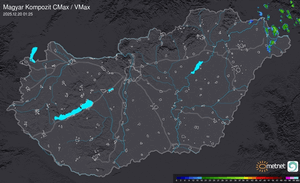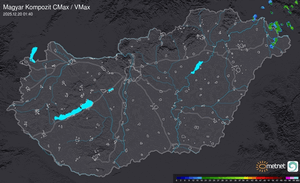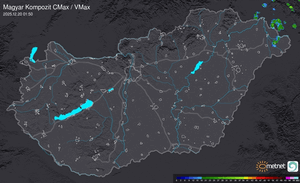
Aktuális hõmérséklet
Aktuális szél
Utolsó kép

Mediterrán ciklon hoz csöppnyi tavaszt és kicsivel több telet
Időjárás-változás | 2026-02-18 12:39
Szabályzat